Word2Vec: The Building Block of Modern NLPs like ChatGPT
Introduction
In the ever-evolving landscape of Natural Language Processing (NLP), Word2Vec stands out as a revolutionary concept, a cornerstone that has significantly shaped the way we approach language in artificial intelligence. This article aims to unravel the intricacies of Word2Vec, explaining its importance, and providing intuitive analogies and code examples to solidify your understanding.
The Birth of Word2Vec
Word2Vec, developed by a team of researchers led by Tomas Mikolov at Google, transformed how machines understand human language. It’s not just a technical milestone; it’s the bridge that allows machines to interpret the nuances of our words.
An Intuitive Analogy
Imagine a bustling marketplace where each stall represents a different word. The proximity of these stalls to one another depends on how often words are used together. For instance, “butter” and “bread” might be neighbors, while “butter” and “bicycle” are at opposite ends of the market. Word2Vec, in essence, is the map of this marketplace.
Core Concepts
Word2Vec encapsulates two models: Continuous Bag of Words (CBOW) and Skip-Gram. CBOW predicts a target word based on context words, while Skip-Gram does the opposite. Think of CBOW as guessing a missing puzzle piece based on surrounding pieces, and Skip-Gram as finding the surrounding pieces when given the central one.
Code Example: Implementing Word2Vec
import gensim
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# Sample sentences
sentences = [['this', 'is', 'a', 'sample', 'sentence'],
['word2vec', 'model', 'example'],
['another', 'sentence'],
['one', 'more', 'sentence']]
# Training the Word2Vec model
model = Word2Vec(sentences, min_count=1)
# Summarize the loaded model
print(model)
# Access vector for one word
print(model.wv['sample'])
# Save model
model.save('model.bin')
# Load model
new_model = Word2Vec.load('model.bin')This code snippet provides a basic example of training a Word2Vec model using gensim in Python.
Visualizing Word Embeddings
One of the most exciting aspects of Word2Vec is its ability to visualize word relationships. By reducing the dimensions of word vectors through PCA, we can plot these words in a two-dimensional space.
!pip install gensim
import gensim
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# Sample sentences
sentences = [['this', 'is', 'Dr', 'Ernesto', 'Lee'],
['Madison', 'born', 'December'],
['Caesar', 'January'],
['Jordan', 'in', 'October']]
# Training the Word2Vec model
model = Word2Vec(sentences, min_count=1)
# Summarize the loaded model
print(model)
# Access vector for one word
print(model.wv['Lee'])
# Save model
model.save('model.bin')
# Load model
new_model = Word2Vec.load('model.bin')
# Extracting the word vectors
word_vectors = model.wv
words = list(word_vectors.index_to_key)
# Reducing dimensions to 2D using PCA
X = word_vectors[words]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
# Creating a scatter plot of the projection
pyplot.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()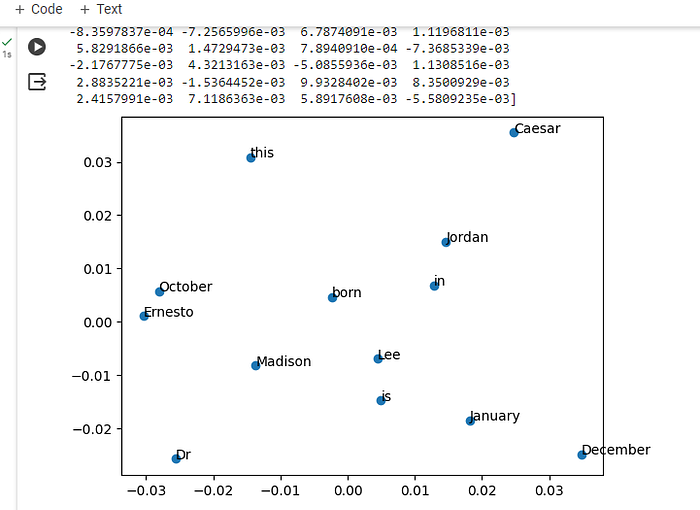
Word2Vec is like a smart program that learns to map out where words should go in an imaginary space based on how often they hang out with other words. It’s like mapping the social circles of words; for example, “king” might be close to “queen” because they often appear together in stories and conversations.
Now, looking at the image you’ve shared, it’s like we’re seeing a snapshot of a school where each word is a student hanging out on the playground. Words that are used in similar contexts, like “January” and “December,” are closer together because they’re both months and they share similar “topics” or “friends” in conversations. “Caesar,” on the other hand, is a bit further away from “January” and “December,” indicating that it’s used in different contexts (like history or literature about Ancient Rome) and doesn’t “hang out” with the months as much in the world of words. Word2Vec helps us see these relationships visually, just like we can see which kids cluster together in different areas on the playground based on their shared interests.
The Importance and Value of Word2Vec
Word2Vec laid the groundwork for subsequent breakthroughs in NLP, including the development of sophisticated models like ChatGPT. It’s not an overstatement to say that without Word2Vec, we wouldn’t have the advanced conversational AI we interact with today.
Why It Matters
- Understanding Context and Meaning: Word2Vec’s ability to capture the context and semantic meaning of words is foundational for machines to understand human language.
- Efficiency and Scalability: It’s a highly efficient model that can handle large datasets, making it practical for real-world applications.
- Versatility: Word2Vec’s embeddings have been used in various applications, from sentiment analysis to language translation.
Conclusion
Word2Vec is not just an algorithm; it’s a paradigm shift in NLP. By mapping words into a high-dimensional space where their semantic relationships are preserved, Word2Vec has paved the way for advanced AI models that understand and generate human language with remarkable accuracy.
As we continue to advance in the field of AI, the principles and insights gained from Word2Vec will undoubtedly remain a crucial part of our journey, reminding us of the profound impact that understanding language has on bridging the human-AI divide.
